
« Digital Armenian » aims at bringing together numerous international actors (public research laboratories, private enterprises, public institutions, etc.) that develop and implement innovative digital solutions for digital humanities, more particularly for corpus linguistics, teaching, promoting, studying the Armenian language and enable data transfer. The conference offer the opportunity to achieve a state of the art for ongoing projects in an interdisciplinary framework and using a comparative approach with similar researches conducted for other languages. It will lay the basis for a collective approach to further Armenian-language data sharing and interoperability on the international stage, in order to improve responses to the challenges facing the Armenian language in the digital age.
The conference offers the opportunity to introduce to the public the latest technologies developed for the Armenian language, considered as a poorly endowed language – that inhibits developing intelligent technologies and also maybe the promotion (through teaching) despite numerous initiatives –, and to share the experience of ongoing projects in order to explore areas of cooperation and to improve the current responses given to the challenges of the Armenian language in the digital age.
Topic of interests
Digital Armenian encourages exchanges around the following topics (non exhaustive list):
- Digital Resources for Armenian (dictionaries, ontologies, written or oral corpora, etc.),
- Digital Humanities applied to Armenian (Stylometry, computational paleography, character recognition, etc.),
- Armenian language and Artificial Intelligence (text analysis, machine translation, speech synthesis, speech recognition, etc.),
- etc.
Core scientific committee
- Chahan Vidal-Gorène (École Nationale des Chartes-PSL, Calfa)
- Victoria Khurshudyan (Inalco, SeDyL, CNRS, IRD)
- Anaïd Donabédian (Inalco, SeDyL, CNRS, IRD)
Next edition
Processing Language Variation: Digital Armenian (DigitAm) 2022. held within the framework of the 2022 International Conference on Language Resources and Evaluation (LREC 2022), Marseille, France, afternoon June 20, 2022.
Call for paper open until April 8th, 2022
Past editions
Digital Armenian 2019 : held at Inalco (Paris), co-organized by Institut National des Langues et Civilisations Orientales (Inalco, Paris), the Structure et Dynamique des Langues laboratory (SeDyL-CNRS, Paris), the Association pour le Traitement Automatique des Langues (ATALA, Paris), the Calfa Association (Paris), the ERTIM laboratory (INALCO, Paris), the French Society for Armenian Studies, and the Laboratory of Excellence EFL (Paris), with the support of the excellence research laboratory EFL (Paris), of the USC Institute of Armenian Studies (USA) and of the Calouste Gulbenkian Foundation (Lisbon).
Armenian Language
Despite being a language with a multisecular written tradition, Armenian lacks significantly digital resources for NLP and linguistic research. Several important projects for particular Armenian varieties exist, as well as a growing interest in NLP resources is observed.
The Armenian language in all its variation encompasses Classical Armenian (5th-10th cen. A.D), preserved exclusively for canonical uses, Middle Armenian (11th-17th cen.), and Modern Armenian (17th cen. – up to present) with its two standards: Modern Eastern Armenian (the official language of the Republic of Armenia, which is also the language of the Armenian communities of Iran and the other ex-Soviet republics) and Modern Western Armenian (spoken by traditional Armenian communities in Europe, the Americas and the Middle East originating mainly from the Ottoman Empire), both standardized in the 19th cen. (Figure 1). Aside from the two standards, the Armenian language continuum includes various dialects, as well as vernacular forms. All the written varieties of the Armenian language use the unique Armenian alphabet.
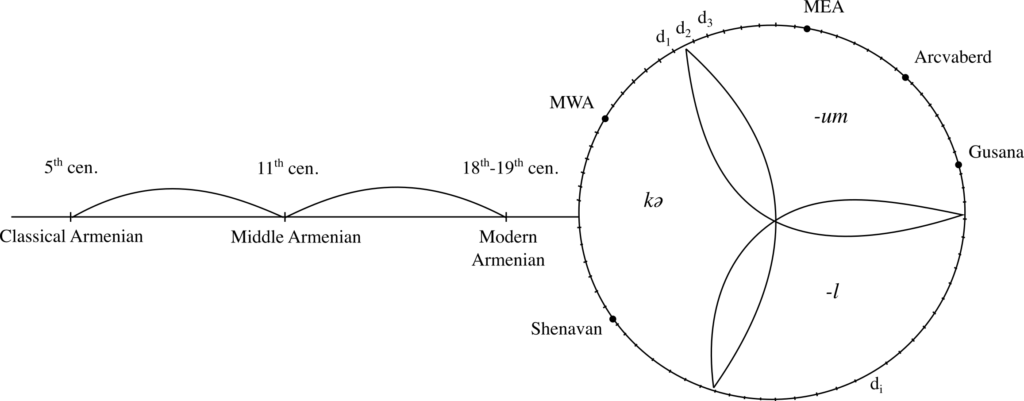
Figure 1: Armenian diachronic and synchronic varieties with di corresponding to a dialectal variety (Vidal et al. 2020:91).




